|
|


Frequently Asked Questions |

|

|

|

|

|
|
|
Frequently Asked Questions |
|
|
|

|

|
Frequently Asked Questions
|
|
|
Frequently Asked Questions |
|
|
|
|
|
|
|
Frequently Asked Questions |
|
|
|
|
|
|
|
||
|
|
MODFLOW is a command-line program rather than a graphical-user interface program. All the input for MODFLOW must be prepared in advance in a text editor or a separate graphical user interface. When MODFLOW is run, it prompts the user for the name of the Name File and then uses the files listed in the Name File to run the model. The input files for MODFLOW can not be edited by running MODFLOW. There are a variety of graphical user interfaces for MODFLOW on the market. Many users find the graphical user interfaces make MODFLOW easier to use. |
Prepare the input files for MODFLOW. Then proceed using one of the methods below. Method 1: Open a command line window. On Windows XP, you do this by first clicking the Windows "Start" button in the lower left and selecting "Run..." then type "cmd" and click the OK button. In the command line window, use the "CD" command to change to the directory to the directory that contains the name file for your model. If you also have a copy of MODFLOW in the same directory as your input files, type the the name of the MODFLOW executable such as "mf2k" or "mf2005". If you don't have a copy of MODFLOW in the same directory as your input files, type the full path for MODFLOW such as "C:\Wrdapp\mf2k.1_18\bin\mf2k.exe". (If the full path includes any spaces, be sure to enclose the full path in quotation marks.) MODFLOW will start and prompt you for the name of the name file. Type the name of the name file and pres the Enter key on the keyboard. Method 2: Create a text file in the same directory as the input files for the model. On the first line of the file enter the full path for MODFLOW such as "C:\Wrdapp\mf2k.1_18\bin\mf2k.exe" followed by a space and then the name of the name file. On the second line write the line "pause". The file might end up looking something like this. C:\Wrdapp\mf2k.1_18\bin\mf2k.exe MyModel.nam pause Save the file. Then change the file extension of the file to ".bat". In Windows Explorer, double-click on the file to start MODFLOW. |
There are several different versions of MODFLOW available. Check https://water.usgs.gov/ogw/modflow/index.html for the version you want. |
This is answered at https://water.usgs.gov/software/. |
|
No. It can only be saved in binary format in the USGS version of MODFLOW. Users would have to change the MODFLOW source code and recompile MODFLOW in order to save the cell-by-cell budget file in ASCII format. However, the some of the cell-by-cell budget terms can be written to the Listing file by setting the budget unit number in the output files to a negative number. For example, set IDRNCB less than zero in the Drain package. |
There are at least four USGS programs that can be used to read data from the cell-by-cell budget file.
Note that the cell-by-cell budget file must be an unstructured non-formatted file to be read by the above programs. To generate such files with versions of MODFLOW not distributed by the USGS, openspec.inc in the MODFLOW source code may need to be modified prior to compiling MODFLOW. See also: How can I read data from a binary file generated by MODFLOW? |
| J. |
First of all, mpif.h is only needed to compile a parallel version of MODFLOW-2000. The serial version of MODFLOW-2000 is not compiled with mpif.h. To compile the serial version of MODFLOW-2000, use the file para-non.f from the source\serial directory. To compile the parallel version of MODFLOW-2000 use the files from the source\parallel directory. One of the files in the source\parallel directory (para-mpi.f) requires mpif.h. You shouldn't use the files from both the source\serial and source\parallel directories; use one or the other but not both. If you do wish to compile a parallel version of MODFLOW, you will need to get a copy of mpif.h. Search the web for it. One place you may be able to get it is http://tell11.utsi.edu/mpich-1.2.5/include/mpif.h To enable the parallel-processing capabilities of MODFLOW-2000, an implementation of MPI must first be installed on your computer(s). MPI software is not distributed by the USGS and must be obtained and installed separately. The mpif.h file and MPI subroutines referenced in the para-mpi.f file and other locations in the MODFLOW source code will be provided as part of the MPI installation. After MPI has been installed, use mpif.h and other source-code files provided with the MPI implementation that is installed on your computer(s) when MODFLOW-2000 is compiled with para-mpi.f. Some implementations of MPI support only certain compilers, so ensure that the MPI implementation you install supports the compiler you will be using to compile MODFLOW-2000. Please refer to page 203 of USGS Open-File Report 00-184 for additional information. |
The convergence criteria such as HCLOSE and RCLOSE in the PCG2 package may be too strict or the number of iterations in the solver may be too small. Adjusting other parameters of the selected solver or changing to a different solver may also be helpful. For large models, the GMG solver can prove helpful. If the solver has the capability of printing out additional information about the solution process such as by setting IPRPCG to 1 in the PCG2 package, it can be worthwhile to examine the solution information to gain insight into what is causing the problem. Use of the wetting capability (first implemented in BCF2 and retained in BCF3, BCF5, LPF and HUF) can result in non-unique solutions because the head in a cell must be higher than some wetting threshold. If a cell starts off wet, it can remain active even if the head drops below the wetting threshold. However, if it starts out dry, it may not be wetted because the head in the neighboring cells may be too low. Use of the wetting capability can cause serious problems with convergence. You can try to avoid this by several methods.
The two most important variables that affect stability are the wetting threshold and which neighboring cells are checked to determine if a cell should be wetted. Both of these are controlled through WETDRY. It is often useful to look at the output file and identify cells that convert repeatedly from wet to dry. Try raising the wetting threshold for those cells. It may also be worthwhile looking at the boundary conditions associated with dry cells. Sometimes cells will go dry in a way that will completely block flow to a sink or from a source. After that happens, the results are unlikely to be correct. It's always a good idea to look at the flow pattern around cells that have gone dry to see whether the results are reasonable. Look for cells or blocks of cells that are completely cut off from the rest of the model either because they were set up that way or because cells around them have gone dry. Such blocks of cells may receive recharge that has nowhere to go. If the Lake package is being used, it may be worth checking whether the value of THETA is appropriate. It can be difficult to get steady-state models without any specified-head boundaries to converge because there may be an imbalance between the amount of water entering and leaving the system. MODFLOW requires that all input use the same length and time units. If you used the wrong units, that may manifest as a problem with convergence. |
Some programs that can read data from binary files generated by MODFLOW include the following.
Note that the binary files must be an unstructured non-formatted file to be read by the above programs. To generate such files with versions of MODFLOW not distributed by the USGS, openspec.inc in the MODFLOW source code may need to be modified prior to compiling MODFLOW. In addition, Graphical User Interface programs for MODFLOW may be able to read such binary files. Binary files generated by MODFLOW are of several types. These include:
If you need to write code to read the binary files, the following descriptions of how the data is saved may help.
|
Use the COMPACT BUDGET option in the Output Control file. |
Example input files are included with MODFLOW. They are in the "data" folder for MODFLOW-2000 or the "test-run" folder for MODFLOW-2005. |
|
Q = -KA(h1 - h0)/(X1 - X0) Where Q is the flow (L3/T) K is the hydraulic conductivity (L/T) A is the area perpendicular to flow (L2) h is head (L) X is the position at which head is measured (L) Conductance combines the K, A and X terms so that Darcy's law can be expressed as Q = -C(h1 - h0) where C is the conductance (L2/T) The flow packages calculate the conductance between cells using some average hydraulic conductivity of the cells, the area of the interface between the cells and the distance between the cell centers. Some of the head-dependent boundary conditions, require the user to specify the conductance. See also: Mehl, S.W. and Hill, M.C., 2010, Grid-size Dependence of Cauchy Boundary Conditions used to Simulate Stream-Aquifer Interactions: Advances in Water Resources. Volume 33, Issue 4, Pages 430–442 |
If the disk on which the files are being written is formatted as FAT or FAT32, the maximum allowed file size is 4 GB minus 1 byte. Larger files can be created if the file system in NTFS. See http://technet.microsoft.com/en-us/library/bb456984 for more information. |
The "STREAM FLOW OUT" budget term can be saved to a cell-by-cell budget file by the Stream (STR) package. It represents the surface water flow out of a stream reach. This is different from other terms normally saved in cell-by-cell budget files which represent either flows among groundwater cells or flows between groundwater cells and boundary features. Note that "STREAM FLOW OUT" represents the total surface water flow out of a reach and not the net flow out of a reach. |
There are a number of things you can do to make MODFLOW run faster without changing the simulated values.
|
| T. |
When you compile MODFLOW, you need to make sure that the code in the file OPENSPEC.inc is correct for your compiler and that it matches what is included in MP6Openspec.inc in the MODPATH source code or the version of OPENSPEC.inc that is part of the ZONEBUDGET source code. Then you need to compile your own version of MODPATH or ZONEBUDGET. In the version of MODFLOW distributed by the USGS, OPENSPEC.inc sets a number of variables that will cause binary files to be written without anything to mark the end of records or to mark the beginning or end of files. With standard Fortran, such markers are included. However, the Fortran standard does not specify what those markers should be. Because of that, different compiler manufacturer have not been consistent about what markers are used. Typically, this results in binary files being generated by a program compiled by one compiler being different from the binary files generated by that same program if the program is compiled by a different compiler. Because of this, binary files are generally incompatible between programs compiled with different compilers. By removing the markers, it is possible to make the files readable by programs written by different compilers. Unfortunately, there isn't a standard way to achieve that goal. (I.e. there isn't a standard way to violate the Fortran Standard!). Hence, OPENSPEC.inc has several versions of some lines and the person compiling the program must choose the right version for their compiler. The comments in OPENSPEC.inc identify which code is appropriate for several popular compilers. |
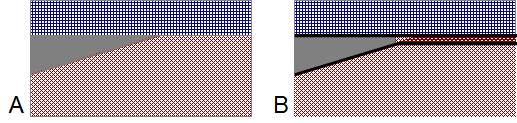
Consider the following geologic cross section with two layers.
When these geologic units are simulated in MODFLOW, the heads will be calculated at a number of nodes in each layer as shown below.
Each of these nodes represents a certain volume of their respective aquifer. These volumes are called cells. Those volumes can be represented in at least two ways. In illustration A below, the volume represented by each node is shown with a tilted bottom whereas in B, the volume is shown with a flat bottom. The advantage of method A is that it makes clear which cells are neighbors of other cells. Flow only occurs between neighboring cells. However, it shows varying elevations for the top of bottom of individual cells. That isn't true. Each cell has a single top elevation and a single bottom elevation. These elevations are defined in the Discretization file.
Method B shows only a single elevation for each cell and method B is the most common way of depicting cells in a cross section of a MODFLOW model. However, beginners frequently ask whether flow occurs through the lines shown in red in the figure below. The short answer is "No"*. Flow only occurs among neighboring cells within layers or between cells that are immediately adjacent vertically. Thus, there can be flow to a maximum of six other cells from any individual cell. The advantage of method A is that it makes that relationship clear. Neither of these methods is ideal because both misrepresent the mathematical model to a certain extent. The best method to use will depend on the ideas you wish to communicate and your audience.
*There is one exception to the explanation given above. In MODFLOW-OWHM, the Horizontal-Flow Barrier package can be used to simulate flow between cells that are adjacent in the horizontal direction but that are in different layers. This capability can be used to simulate faults that have moved different geologic units next to one another in the horizontal direction. |
"Virtual memory" is used when your computer does not have enough physical memory to run the model so some data that would normally be in memory is saved in the hard drive instead. You need to have enough hard drive space to store the extra data. Another reason you might get this message is that you are running a 32-bit version of MODFLOW and the model requires more than 4 gigabytes of memory. If that is the case, you need to run a 64-bit version of MODFLOW. There are 64-bit versions of MODFLOW-NWT and MODFLOW-OWHM distributed by the USGS. However, there are only 32-bit versions of MODFLOW-2005 distributed by the USGS at the time of this writing (MODFLOW-2005 version 1.11). If you need a 64-bit version of MODFLOW-2005, you may need to compile it yourself. |
Yes. |
The heads printed by the Head-Observation Package are interpolated from the calculated heads in surrounding cells. See the Head-Observation Package for details. The heads printed in the listing file or a head output file are the heads calculated at the cell center. |
|
MODFLOW does not simulate solute transport. However, the output from MODFLOW can be used in solute transport programs such as MT3DMS or MT3D-USGS. |